I am always confused about where I should go on holiday. You might also face similar conditions because there are a variety of choices. There are some cases where we have only two choices, and we have to go with one. For example, flipping a coin, and we know that either it would be head or tail. The decision acts on the decision tree concept.
But when we ask multiple people about the best holiday destination. Most of the people give different answers. And we might go with the maximum time suggested holiday destination. This decision acts on the random forest concepts.
Now, random forest vs decision tree is one of the most popular search queries as people get confused with both algorithms. Below, we have given useful details about both algorithms. So, without confusing you more, let’s delve into the concept of random forest and decision tree.
What is a decision tree?
Table of Contents
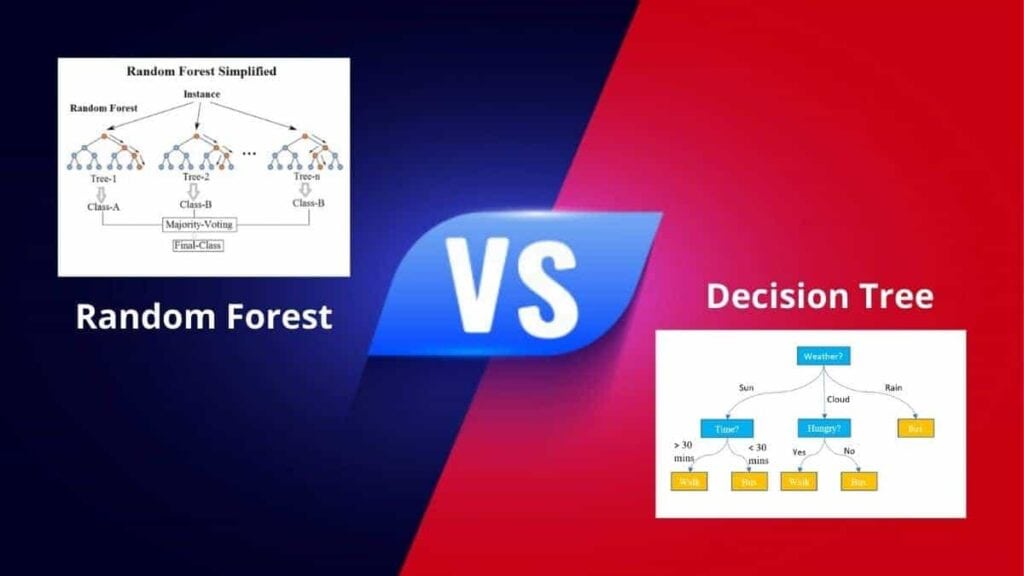
It is an algorithm with a tree-like structure that a user uses to determine the course of action. Each branch of it shows the possible reaction, occurrence, or decisions.

The algorithm acts on certain features that we have discussed below. Here is the key point that the user must keep in mind, and that is starting node must have the dataset of one category. The layer of the tree will split the data as per the true or false decisions.
| Key point: It is the supervised learning algorithms that are basically used for machine learning and data science. It can work in both regression and classification algorithms. |
What is a random forest?
The name suggested that forest means having multiple trees that are created randomly. That is why there is a direct approach or relationship between the number of trees within the forest.

This means that the more you have the number of trees, the more accuracy would be in your result.
| Key point: In the random forest, the feature of forest creating is not as similar as that of the decision tree (that works on the data gain or gain index approach). But the random forest algorithm works as a supervised classification algorithm. |
What are the advantages of random forest and decision tree?
| Advantage of random forest | Advantage of decision tree |
| It creates high accurate classifiers. | It is mostly used for data exploration. |
| Random forest runs over the large databases more effectively. | The numerical and categories feature can handle in the input feature. |
| The variable importance estimation is obtained as the process part of Random forest. | Decision tree has little human intervention. |
| Even without variable deletion, several inputs can easily handle. | The decision tree runs the tree node algorithm in a parallel way. |
What are the disadvantages of random forest and decision tree?
| Disadvantage of random forest | Disadvantage of decision tree |
| It proceeds quite slow. | It overfits some algorithms. |
| The random tree can not use for linear methods. | The decision tree pruning process is quite large. |
| It works worse for the high dimension data. | It has really complicated calculations. |
| Random Forest isn’t objective with certain features. | It offers an unguaranteed optimization. |
Head to head comparison: Random forest vs Decision tree
| Random forest | Decision tree |
| It depends on the decision tree output. | It makes a decision independently. |
| Random forest helps in reducing the risk of overfitting. | There are higher chances of overfitting. |
| It provides accurate results. | The results of the decision tree have less accuracy. |
| It is quite complex to work on. | It is easy to work with the decision tree. |
| Random forest makes random predictions. | The decision tree provides 50-50 chances of correction to each node. |
| It works on classification algorithms. | It works on both classification and regression algorithms. |
| Random Forest works quite slow. | It is much faster than a random forest. |
| There is no need to normalize the value. | The decision tree requires the normalization of the value. |
| It is used for linear models. | It is used for the non-linear model. |
| Random forest works worse with large datasets. | The decision tree performs very well with large datasets. |
So, Which is better: Random forest or Decision tree?
As we can see, that decision tree is much easier to understand and interpret. On the other hand, the random forest includes various decision trees that make it quite complicated to interpret.
But, here is the good news – it is not something that is impossible to interpret the random forest algorithms.
Apart from this, the random forest has quite a feature of higher training time. Therefore, you must consider it as you can increase the trees within a random forest; that results in increasing the training time also.
But finally, we can say that despite dependency and instability on a certain set of features, the decision tree can help as it is quite easier to interpret and much faster to train. A person who has little knowledge of data science and machine learning can use the decision tree for making a quick decision. And he/she can also go with the random forest to make the correct decisions.
Conclusion
The random forest has multiple trees that are classified over the training data’s random sample. It has been seen that random forest provides more accurate results as compared to the single decision trees.
If you do not have enough time to work over a model, just go for the decision tree. But if you have enough time to reveal the accurate results. Go with the random forest. I have detailed all the necessary differences among the random forest vs decision tree.
If you still have any queries regarding the topic. Comment in the below section, and let me help you in the best possible way to solve your random forest vs decision tree queries.