
We all study geometric shapes, formulas, and concepts in our student lives. But at that time, we did not focus on the types of geometry; we just knew how to calculate the area of a circle, determine the volume of a cuboid, etc.
We all know geometry is a complex area of mathematics. This is because we need to learn a wide range of formulas for different objects and shapes and think logically while applying the formulas.
We get perplexed when we study the different types of geometry and the areas or concepts they cover.
So, let’s explore major geometry types along with other concepts.
What is geometry?
Table of Contents
Geometry comes from the Greek words ‘geo’ (earth) and metric(measurement), so it means ‘earth measurement’.
It is a wide branch of mathematics that deals with the study of shapes, sizes, dimensions, etc., of space.
Major types of Geometry?
Geometry is categorized in Euclidean and non-Euclidean geometry.
Euclidean Geometry consists of plain, solid, and spherical geometry.
Non-Euclidean geometry involves hyperbolic and elliptic geometry.
Here, we will discuss Euclidean Geometry.
There are three major types of Euclidean geometry.
- Plane Geometry
- Solid Geometry
- Spherical Geometry
Plane Geometry
It is also known as 2-D geometry because it works on 2-D flat shapes, such as circles, triangles, squares, semicircles, etc., which can be drawn on paper. In this type of geometry, we include the length and breadth of the shapes and avoid the depth.
Terminology of Plane Geometry-
Point
A dot represents a point on the plane. A point is dimensionless but has a position. We consider the point a place rather than a thing.
Line
A line combines infinite points, is endless, straight, and has no thickness. It can be extended to infinity. In geometry, we take the horizontal line as the x-axis and the vertical line as the y-axis.
Line Segment
It is part of a line. A line with a starting and ending point is called a line segment.
Line segment
Ray
A line with a starting point but no ending point is known as a ray, such as a Sun ray.
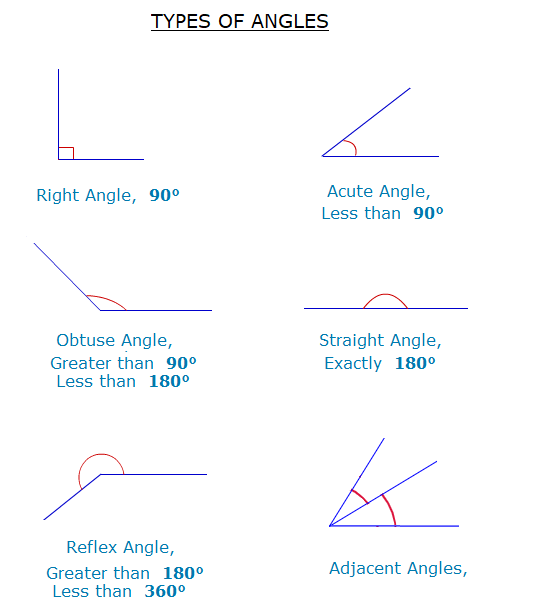
Geometric Angles
An angle is a formation of two rays. When two rays cut each other, they make an angle and share the common endpoint(vertex) of rays.
Acute Angle
An angle that can vary between 0 and 90 degrees is called an acute angle. In simple words, you can say an angle that is smaller than a right angle(90 degrees) is known as sharp(acute angle)
Obtuse Angle– An angle that is more than a right angle(90 degrees) is an obtuse angle. It should be less than 180 degrees.
Right Angle- A right angle has a value of 90 degrees.
Straight Angle- An angle formed by a straight line is a straight angle. It is at an angle of 180 degrees.
Plane Figures in Geometry-
Polygons- Polygons are closed plane figures in geometry. As the name suggests poly(multi) gons(sides) are figures of multiple sides. For example a triangle is a figure of three sides, a rectangle is a figure of four sides.
The sum of internal angles of a polygon= (n-2)х180
Each interior angle= sum of internal angles/sides
Where n is the number of sides.
Suppose we need to calculate the sum of the internal angle of a pentagon.
Apply the formula
Here n=5
(5-2).180
3.180=540 degrees is the sum of the internal angle of a pentagon.
Each interior angle= 540/5=108
Also Read
- Geometry vs Trigonometry
- How Statistics Math Problems
- Top 7 Applications of Mathematics In Statistics
Different types of polygon
- Triangles( 3 sides)
- Quadrilaterals( 4 sides)
- Pentagon( 5 sides)
- Hexagon( 6 sides)
- Heptagon( 7 sides)
- Octagon (8 sides)
- Nonagon (9 sides)
- Decagon (10 sides)
Triangle
sides=3
The sum of internal angles= 180 degrees.
Types-
Equilateral Triangle- It has 3 equal sides, and each angle is 60 degrees.
Isosceles Triangle- It has two sides and angle equals.
Quadrilateral
Sides=4
Sum of internal angles=360 degrees
Types-
Square-It has 4 equal sides and vertices at right angles.
A rectangle has opposite sides equal, and all angles are 90 degrees.
Parallelogram-It has two pairs of parallel sides where opposite sides and angles are equal.
Rhombus-It has all the four sides to be of equal length but their internal angles are not of 90 degrees.
Trapezium- It has one pair of opposite sides which are parallel to each other.
Pentagon
sides= 5
The sum of internal angles= 540 degrees.
Hexagon
It has six straight sides and angles.
sides=6
The sum of internal angels=720 degrees.
Heptagon
It is a plane figure with seven sides and seven angles.
The sum of internal angles=900 degrees.
Octagon
It has eight sides and eight angles.
The sum of internal angles= 1080 degrees.
Nonagon
It has 9 sides and 9 angels.
Sum of internal angles=1260 degrees
Decagon
It has 10 sides and 10 angles
Sum of internal angles=1440
Circle in Geometry
When we talk about plane types of geometry, it includes circles with other shapes.
A circle is a closed curved shape from the center point. It consists of radius, diameter, chord etc.
Similarity of circle- Same shape or have an equal angle, but the size is different.
Congruence of circle-Same shape and size.
Solid Geometry
Solid geometry covers the study of 3-D (three-dimensional) shapes such as cubes, cylinders, and spheres. It includes the three dimensions of shapes: length, breadth, and height.
It is one of the complex types of geometry.
Our surrounding objects are three-dimensional. Faces, edges, and vertices are some features of 3-D shapes. Let’s discuss them one by one.
Edges
These are the line segments that join one vertex to the other. In simple words, these are the faces that meet in a straight line. Different shapes have different edges.
For example, a cube has 12 edges, a square pyramid has 8 edges.
Faces
A face is a flat surface enclosed by its edges. It should be a 2-D figure for a 3-D shape.
A cube has 6 faces and a square pyramid has 5 faces.
Vertices
Where the edges of any 3-D shape meet at each other is defined as a vertex. It is the point where the adjacent sides of the polygon meet.
A cube has 8 vertices and a triangular pyramid has 4 vertices.
Spherical Geometry
It studies the 2-D surface of a sphere. The terms like a ball or other sphere objects are used for the surface and the 3-D interior, but in this context, the word sphere is used for the 2-D surface.
Conclusion
I hope now you are familiar with the types of geometry. Geometry is a vast area to cover as it belongs to different 2-D and 3-D shapes with their measurements.
This blog has covered the major geometry types that will help you understand geometrical concepts. If you want to be a master of geometry, you need to strengthen your basic concepts and logical thinking. Get the best online geometry homework help from the experts and enjoy high grades.
Frequently Asked Questions
Who is the father of geometry?
The great mathematician Euclid is the father of geometry. He worked very hard to explain the concepts of points, lines, and shape with the dimensions and determine various factors such as area, volume, and perimeter of the shapes.
Plain and solid, which are the most complex types of geometry?
Well, both types are complex, but plain geometry does not involve the depth of the shapes, so it is relatively easy. Because here, we do not focus on the formulas of volume and other related factors. Whereas in solid geometry, we need to concentrate on the length, breadth, and depth of the shapes, as a result of which the number of formulas increases, and it doesn’t seem easy to learn for us.

